
Los datos de series temporales consisten en puntos de datos unidos a marcas de tiempo secuenciales. Las ventas diarias, los valores de temperatura por hora y las mediciones de segundo nivel en un proceso químico son algunos ejemplos de datos de series temporales.
Los datos de series temporales tienen características diferentes a los datos tabulares ordinarios. Por ello, el análisis de series temporales tiene su propia dinámica y puede considerarse un campo aparte. Existen libros de más de 500 páginas que tratan en profundidad los conceptos y técnicas del análisis de series temporales.
Pandas fue creado por Wes Mckinney para proporcionar una herramienta eficiente y flexible para trabajar con datos financieros que son una especie de serie temporal. En este artículo, repasaremos 4 funciones de Pandas que se pueden utilizar para el análisis de series temporales.
Necesitamos datos para los ejemplos. Empecemos por crear nuestros propios datos de series temporales.
Los datos de series temporales tienen características diferentes a los datos tabulares ordinarios. Por ello, el análisis de series temporales tiene su propia dinámica y puede considerarse un campo aparte. Existen libros de más de 500 páginas que tratan en profundidad los conceptos y técnicas del análisis de series temporales.
Pandas fue creado por Wes Mckinney para proporcionar una herramienta eficiente y flexible para trabajar con datos financieros que son una especie de serie temporal. En este artículo, repasaremos 4 funciones de Pandas que se pueden utilizar para el análisis de series temporales.
Necesitamos datos para los ejemplos. Empecemos por crear nuestros propios datos de series temporales.
import numpy as np
import pandas as pd
df = pd.DataFrame({
"date": pd.date_range(start="2020-05-01", periods=100, freq="D"),
"temperature": np.random.randint(18, 30, size=100) +
np.random.random(100).round(1)
})
df.head()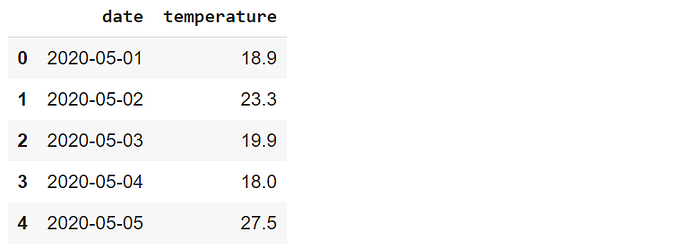
(image by author)
Hemos creado un marco de datos que contiene mediciones de temperatura durante un periodo de 100 días. La función date_range de Pandas puede utilizarse para generar un rango de fechas con una frecuencia personalizada. Los valores de temperatura se generan de forma aleatoria utilizando las funciones Numpy.
Ahora podemos empezar con las funciones.
1. Shift
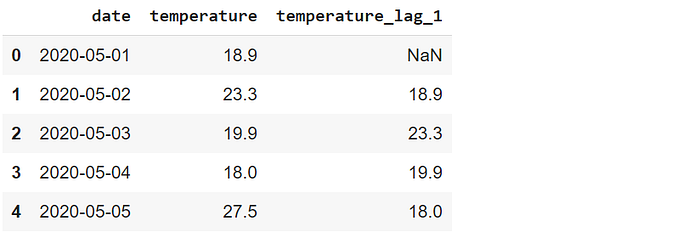
Es una operación habitual para desplazar los datos de las series temporales. Podemos necesitar hacer una comparación entre características retardadas o principales. En nuestro marco de datos, podemos crear una nueva característica que contenga la temperatura del día anterior.
df["temperature_lag_1"] = df["temperature"].shift(1) df.head()
(image by author)
El valor escalar que se pasa a la función de desplazamiento indica el número de períodos a desplazar. La primera fila de la nueva columna se rellena con NaN porque no hay ningún valor anterior para la primera fila.
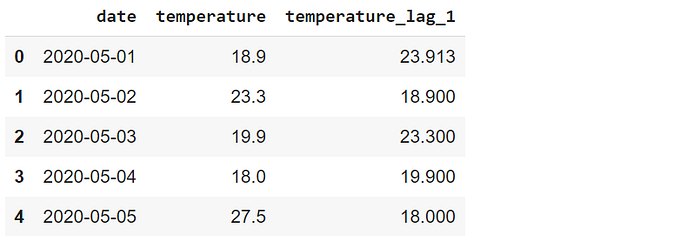
El parámetro fill_value puede utilizarse para rellenar los valores que faltan con un escalar. Sustituyamos el NaN por el valor medio de la columna de temperatura.
df["temperature_lag_1"] = df["temperature"]\ .shift(1, fill_value = df.temperature.mean()) df.head()
(image by author)
Si le interesan los valores futuros, puede desplazarse hacia atrás pasando valores negativos a la función de desplazamiento. Por ejemplo, "-1" lleva la temperatura al día siguiente.
2. Resample
Otra operación habitual que se realiza con los datos de las series temporales es el remuestreo. Consiste en cambiar la frecuencia de los periodos. Por ejemplo, podemos estar interesados en los datos de temperatura semanales en lugar de las mediciones diarias.
La función de remuestreo crea grupos (o bins) de un interno especificado. A continuación, podemos aplicar funciones de agregación a los grupos para calcular el valor basado en la frecuencia remuestreada.
Calculemos las temperaturas medias semanales. El primer paso es remuestrear los datos a nivel de semana. A continuación, aplicaremos la función de media para calcular el promedio.
df_weekly = df.resample("W", on="date").mean()
df_weekly.head()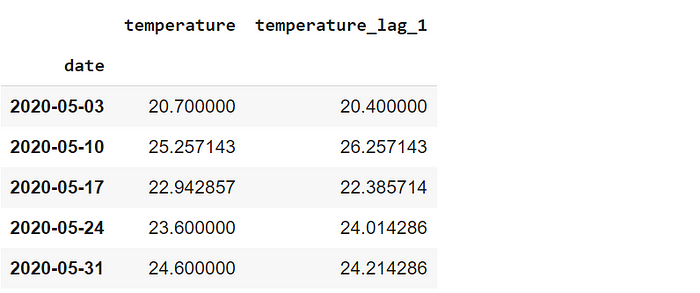
(image by author)
El primer parámetro especifica la frecuencia de remuestreo. "W" significa semana, sorprendentemente. Si el marco de datos no tiene un índice fecha-hora, la columna que contiene la información relacionada con la fecha o la hora debe pasarse al parámetro on.
3. Asfreq
La función asfreq proporciona una técnica diferente para el remuestreo. Devuelve el valor al final del intervalo especificado. Por ejemplo, asfreq("W")devuelve el valor del último día de cada semana.
Para utilizar la función asfreq, debemos establecer la columna de la fecha como índice del marco de datos.
df.set_index("date").asfreq("W").head()(image by author)
Como estamos obteniendo un valor en un día concreto, no es necesario aplicar una función de agregación.
4. Rolling
La función rolling puede utilizarse para calcular la media móvil, que es una operación muy común para los datos de las series temporales. Crea una ventana de un tamaño determinado. A continuación, podemos utilizar esta ventana para realizar cálculos a medida que se desplaza por los puntos de datos.
La figura siguiente explica el concepto de balanceo.
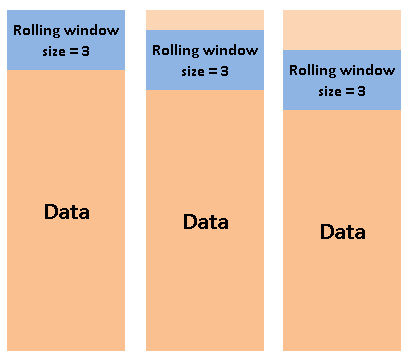
(image by author)
Vamos a crear una ventana móvil de 3 y utilizarla para calcular la media móvil.
df.set_index("date").rolling(3).mean().head()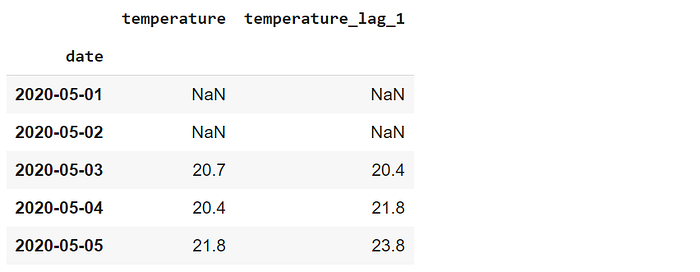
(image by author)
Para cualquier día, los valores muestran la media del día y de los 2 días anteriores. Los valores de los 3 primeros días son 18,9, 23,8 y 19,9. Por tanto, la media móvil del tercer día es la media de estos valores, que es de 20,7.
Los 2 primeros valores son NaN porque no tienen los 2 valores anteriores. También podemos utilizar esta ventana móvil para cubrir el día anterior y el siguiente para cualquier día. Se puede hacer estableciendo el parámetro de centro como verdadero.
df.set_index("date").rolling(3, center=True).mean().head()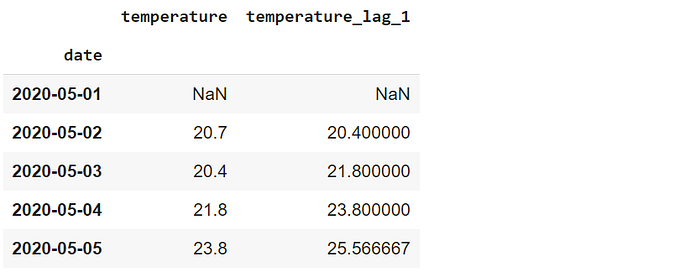
(image by author)
Los valores de los 3 primeros días son 18,9, 23,8 y 19,9. Así, la media móvil del segundo día es la media de estos 3 valores. En esta configuración, sólo el primer valor es NaN porque sólo necesitamos 1 valor anterior.
Conclusión
Hemos cubierto 4 funciones de Pandas que se utilizan habitualmente en el análisis de series temporales. El análisis predictivo es una parte esencial de la ciencia de datos. El análisis de series temporales es el núcleo de muchos problemas que el análisis predictivo pretende resolver. Por lo tanto, si usted planea trabajar en el análisis predictivo, definitivamente debe aprender a manejar los datos de series temporales.
Gracias por leer este artículo. Por favor, hazme saber si tienes algún comentario.







