
A menudo me preguntan "¿en qué tipo de proyecto de aprendizaje automático debería trabajar?".
Y suelo responder con "sigue tu curiosidad".
¿Por qué?
Porque, debido a lo experimental que es el aprendizaje automático, lo mejor es que descubras las cosas jugueteando. Probando cosas que podrían no funcionar.
Sin embargo, los proyectos de aprendizaje automático ya no son obras de magia. El dispositivo en el que estás leyendo esto probablemente utiliza el aprendizaje automático de varias maneras diferentes de las que no eres consciente (ver el aprendizaje automático implícito de Apple más abajo).
Y suelo responder con "sigue tu curiosidad".
¿Por qué?
Porque, debido a lo experimental que es el aprendizaje automático, lo mejor es que descubras las cosas jugueteando. Probando cosas que podrían no funcionar.
Sin embargo, los proyectos de aprendizaje automático ya no son obras de magia. El dispositivo en el que estás leyendo esto probablemente utiliza el aprendizaje automático de varias maneras diferentes de las que no eres consciente (ver el aprendizaje automático implícito de Apple más abajo).
Dicho esto, este número de ML Monthly (edición de abril de 2021) recoge diferentes mejores prácticas de diseño de empresas que utilizan el aprendizaje automático a escala mundial.
Y después de leerlas, empezarás a notar que hay muchas coincidencias en cómo se hacen las cosas. Esto es algo bueno. Porque los solapamientos son lo que puedes utilizar para tus propios proyectos.
A medida que los modelos y el código de aprendizaje automático se vuelven más y más reproducibles, notarás un tema general aquí: el aprendizaje automático es un problema de infraestructura.
Lo cual es algo que ya sabías desde el principio: "¿cómo puedo llevar los datos de un lugar a otro de la forma más rápida y eficiente posible?".
Si estás pensando en trabajar en tus propios proyectos de aprendizaje automático, lee cada una de las directrices que aparecen a continuación y prueba los materiales de la sección bonus, pero recuerda que ninguno de ellos sustituirá los conocimientos que adquieras experimentando tú mismo (directrices, schmuidelines).
Nota: He utilizado los términos aprendizaje automático e inteligencia artificial (IA) indistintamente a lo largo de este artículo. Puedes leer "sistema de aprendizaje automático" como "sistema de IA" y viceversa.
Leer tambien: 10 Líderes en Ciencia de Datos que Deberías Seguir
Directrices de la interfaz humana de Apple para el aprendizaje automático
Estoy escribiendo estas líneas en un MacBook de Apple en una biblioteca donde puedo ver al menos otros 6 logotipos de Apple. Esta mañana he visto a dos personas delante de mí pagar su café con sus iPhones.
Los dispositivos de Apple están por todas partes.
Y todos ellos utilizan el aprendizaje automático de muchas maneras diferentes, para mejorar las fotos, para preservar la vida de la batería, para permitir las búsquedas de voz con Siri, para sugerir palabras para escribir rápidamente.
Las directrices de interfaz humana de Apple para el aprendizaje automático comparten cómo piensan y cómo animan a los desarrolladores a pensar en el uso del aprendizaje automático en sus aplicaciones.
Empiezan con dos preguntas de alto nivel y las desglosan a partir de ahí:
- ¿Cuál es el papel del aprendizaje automático en tu aplicación?
- ¿Cuáles son las entradas y salidas?
En cuanto a la función del aprendizaje automático en su aplicación, se preguntan si es fundamental (necesario) o complementario (agradable). ¿Es privado o público? ¿Es visible o invisible? ¿Es dinámico o estático?
Para las entradas y salidas (soy un gran fan de esta analogía porque es similar a las entradas y salidas de un modelo de ML) discuten lo que una persona pondrá en su sistema y lo que su sistema le mostrará.
¿Una persona le da al modelo una retroalimentación explícita? Es decir, ¿le dice a tu modelo si está bien o mal? ¿O el sistema recoge información implícita (información que no requiere que la persona haga ningún trabajo adicional, aparte de utilizar la aplicación)?
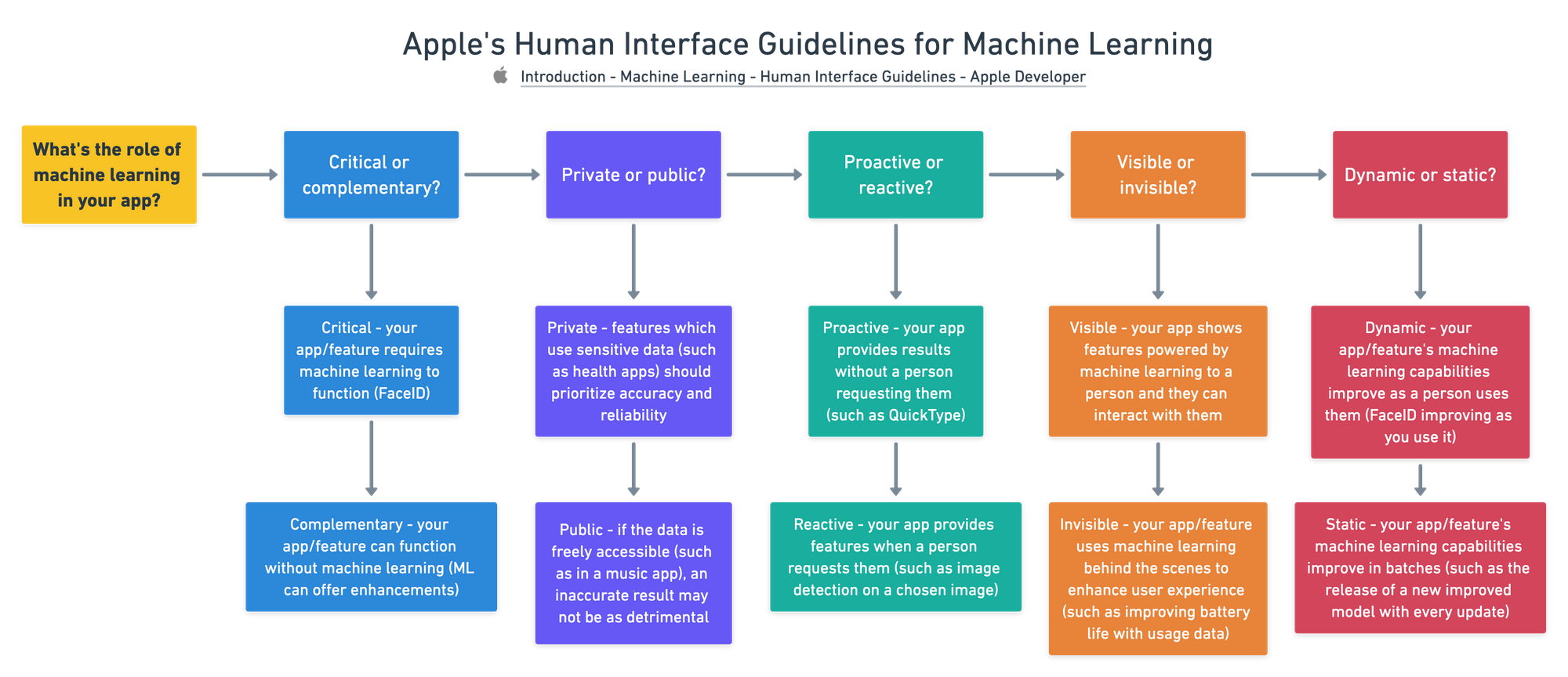
Questions to think about when asking what role machine learning plays in your app/feature. Source:https://developer.apple.com/design/human-interface-guidelines/machine-learning/overview/roles/
Leer también: Personaliza Tus Jupyter Notebooks
Investigación sobre las personas y la IA (PAIR) de Google
Los principios de diseño de Google para la IA pueden encontrarse en su guía People and AI Research (PAIR).
La guía PAIR también viene acompañada de un gran glosario con los diferentes términos de aprendizaje automático que encontrarás en este campo (hay muchos). Desglosa el diseño de un proyecto de IA en seis secciones.
Necesidades del usuario + Definición del éxito
- ¿Dónde está la intersección entre lo que la IA es capaz de hacer y lo que la gente que utiliza su servicio necesita?
- ¿Debe automatizar (eliminar una tarea dolorosa) o aumentar (mejorar) con la IA?
- ¿Cuál es el resultado ideal?
Recogida y evaluación de datos
- Convierta los requisitos de una persona en requisitos de datos (todo empieza con los datos)
- ¿De dónde proceden los datos? (¿se obtienen de forma responsable?)
- Construya, ajuste y afine su modelo (los buenos modelos comienzan con buenos datos)
Modelos mentales (establecimiento de expectativas)
- ¿Qué cree una persona que su sistema de ML puede lograr?
Explicabilidad + confianza
- Los sistemas de IA se basan en la probabilidad (y pueden dar resultados extraños), ¿cómo se puede explicar esto?
- ¿Qué información debería saber una persona sobre cómo ha tomado una decisión un modelo de inteligencia artificial? (niveles de confianza, "le mostramos esto porque le gustó aquello...")
Retroalimentación y control
- ¿Cómo puede una persona dar retroalimentación para ayudar a su sistema a mejorar?
Errores + Fracaso Gracioso
- ¿Qué es un "error" y qué es un "fracaso"? (un coche autodirigido que se detiene en un semáforo en verde podría ser un error, pero saltarse un semáforo en rojo podría ser un fallo)
- Los sistemas de ML no son perfectos y su sistema acabará fallando, ¿qué hacer cuando lo haga?
Cada sección viene con una hoja de trabajo para practicar lo que has aprendido.
Una tendencia que notarás después de repasar las directrices (especialmente PAIR) es la de establecer expectativas. Hay que ser muy franco con lo que el sistema es capaz de hacer. Si una persona espera que su sistema sea mágico (como a menudo se presenta el ML) pero no es consciente de sus limitaciones, puede quedar decepcionada.
Directrices de diseño de Microsoft para la interacción entre humanos e inteligencia artificial
Las directrices de diseño de Microsoft para la interacción entre humanos e inteligencia artificial abordan el problema en cuatro etapas:
- Inicialmente (¿qué debe saber una persona cuando utiliza su sistema por primera vez?)
- Durante la interacción (¿qué debería ocurrir mientras una persona utiliza su servicio?)
- Cuando se equivoca (¿qué ocurre cuando su sistema se equivoca?)
- Con el tiempo (¿cómo mejora su sistema con el tiempo?)
Verá que las directrices de Microsoft le llevan a ponerse en la piel de una persona que utiliza su sistema de ML. Y de nuevo vemos una tendencia.
Problema → Crear solución (ML o no) → Establecer expectativas → Permitir retroalimentación → Tener un mecanismo para cuando está mal → Mejorar con el tiempo (volver al principio).

Microsoft's guidelines for Human-AI interaction cards, starting with initial stages through to what to do as a person interacts with your machine learning system over time. Source: https://www.microsoft.com/en-us/research/project/guidelines-for-human-ai-interaction/
Guía de campo de Facebook para el aprendizaje automático
Mientras que los recursos anteriores han adoptado el enfoque de un sistema global de ML, la Field Guide to Machine Learning de Facebook se centra más en el aspecto de la modelización.
Su serie de vídeos divide un proyecto de modelado de aprendizaje automático en seis partes:
- Definición del problema: ¿qué problema intentas resolver?
- Datos: ¿de qué datos se dispone?
- Evaluación: ¿qué define el éxito?
- Características: ¿qué características de los datos se ajustan mejor a su medida del éxito?
- Modelo: ¿qué modelo se adapta mejor al problema y a los datos que tiene?
- Experimentación: ¿cómo se puede repetir y mejorar los pasos anteriores?
Pero a medida que el aspecto de la modelización en el aprendizaje automático se hace más accesible (gracias a los modelos preentrenados, las bases de código existentes, etc.), es importante tener en cuenta todas las demás partes del aprendizaje automático.
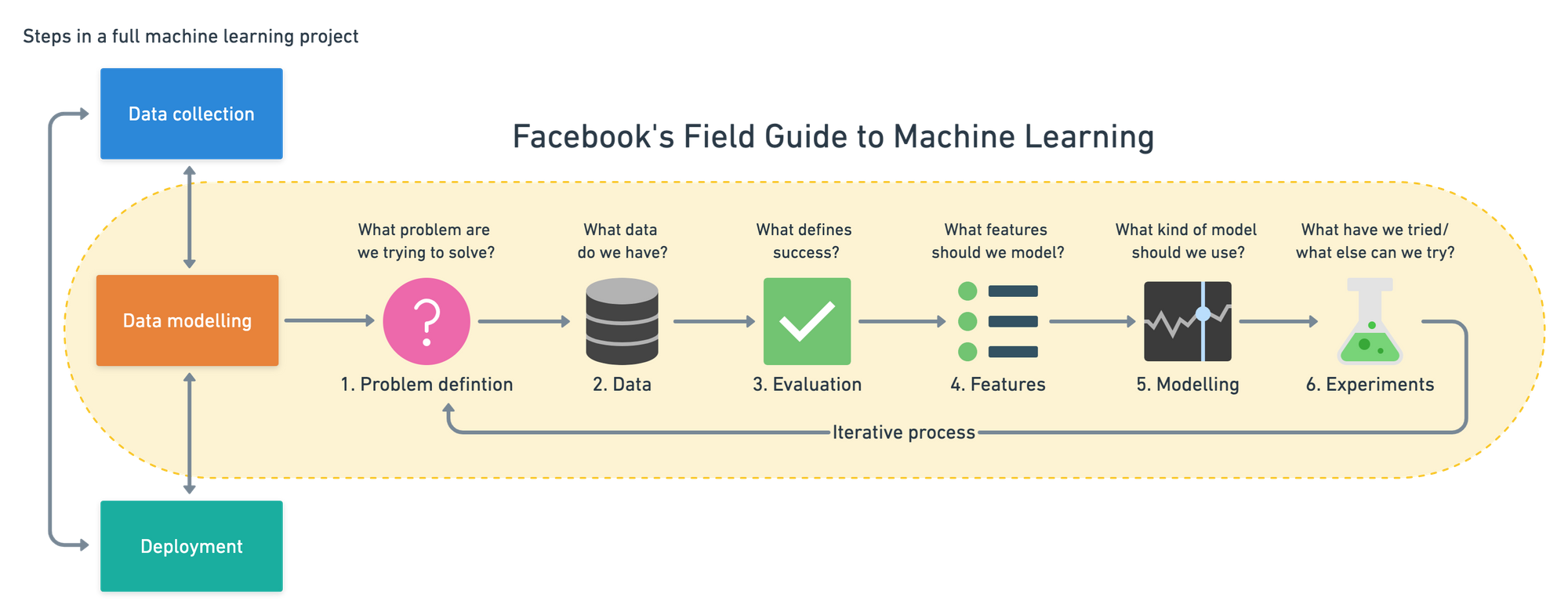
I used Facebook's Field Guide to Machine Learning as the outline of the Zero to Mastery Data Science and Machine Learning Course. You can also read an expanded version of these steps on my blog.
Los 3 principios de Spotify para diseñar productos con tecnología ML
¿Cómo se construye un servicio que proporciona música a 250 millones de usuarios en todo el mundo?
Empiezas por ser manual antes de ser mágico (principio 3) y haces continuamente las preguntas correctas (principio 2) para identificar dónde se encuentran las fricciones de los usuarios de tu servicio (principio 1).
La frase anterior es un juego de palabras de los tres principios de Spotify para diseñar productos basados en el aprendizaje automático.
Principio 1: Identificar la fricción y automatizarla
Cualquier punto en el que una persona tenga dificultades para alcanzar sus objetivos mientras utiliza tu servicio puede considerarse una fricción.
Imagina a una persona que busca música nueva en Spotify y no encuentra nada que se ajuste a sus gustos. Esto podría perjudicar la experiencia de alguien.
Spotify se dio cuenta de esto y utilizó sistemas de recomendación basados en el aprendizaje automático para crear Discover Weekly (lo que estoy escuchando actualmente), una lista de reproducción que se refresca con música nueva cada semana.
Y en mi caso, parece que deben haber seguido sus otros dos principios mientras la creaban, porque estas canciones que estoy escuchando son un éxito.
Principio 2: Haz las preguntas adecuadas
Pregunta. Preguntar. Preguntar. Si no lo sabes, puedes acabar diseñando un producto en la dirección equivocada.
Al igual que muchos de los otros pasos de las directrices anteriores te retan a pensar desde el punto de vista de la persona que utiliza tu servicio, este es el objetivo de hacer las preguntas correctas: averiguar qué problemas tienen tus clientes y ver si puedes resolverlos utilizando el aprendizaje automático.
Principio 3: Ir a lo manual antes de ir a lo mágico
¿Ha encontrado una fuente de fricción?
¿Puede resolverla sin el aprendizaje automático?
¿Qué tal si empiezas con una heurística (una idea de cómo deberían funcionar las cosas)?
Por ejemplo, si fueras Spotify e intentaras crear una lista de reproducción de música nueva que le interesara a alguien, ¿cómo clasificarías algo como nuevo?
Tu heurística de partida podría ser que cualquier cosa de más de 30 días no se clasificaría como nueva.
Después de probar múltiples heurísticas e hipótesis (un proceso manual), podrías volver a revisar si el aprendizaje automático podría ayudar o no. Y gracias a tus experimentos, lo harías desde un punto de vista muy bien informado.
Leer también: Construyendo Una Sistema de Recomendación de Productos Con Filtrado Colaborativo
Del big data al good data por Andrew Ng
Andrew Ng presentó una charla en la reciente conferencia de Scale sobre el movimiento de los sistemas de ML de los grandes datos a los buenos datos. Y Roboflow hizo un gran resumen de los puntos principales - todos los cuales hablan de las cosas que hemos discutido anteriormente.
Algunos de mis favoritos incluyen:
- Llegar al despliegue es un punto de partida más que la línea de meta (cerrar la brecha de prueba de concepto y producción)
- Del big data al good data (la tarea más importante de MLOps es garantizar datos de alta calidad en todas las fases del ciclo de vida del proyecto de ML y no todas las empresas tienen acceso al big data)
- Congela tu código base e itera sobre tus datos (para muchos problemas el modelo es un problema resuelto, los datos son lo que se necesita)

Andrew Ng on the importance of thinking about good data as well as big data. Source: https://scale.com/events/transform/videos/big-data-to-good-data
Aprender más
Todo lo anterior son directrices sobre cómo pensar en la construcción de sistemas potenciados por Machine Learning. Pero no muestran las herramientas ni cómo hacerlo.
Los siguientes son recursos adicionales que recomendaría para llenar los vacíos dejados por los anteriores.
Escoge uno y lee/trabaja con todos los materiales/laboratorios mientras construyes tu propio proyecto de ML.
- Engineering best practices for machine learning (Software Engineering 4 Machine Learning) - una guía completa sobre el desarrollo de sistemas de software con componentes de aprendizaje automático.
- Machine Learning Engineering Book por Andriy Burkov - una tienda de una sola parada para muchas de las directrices y pasos discutidos anteriormente, tengo este libro en mi escritorio y lo uso como una referencia.
- CS329s: Machine Learning System Design - un curso completo de Stanford que cubre todos los pasos que se dan en el diseño de un sistema de aprendizaje automático. Dirigido por Chip Huyen, con conferencias invitadas (incluida una de su servidor) de ingenieros de muchas empresas de aprendizaje automático.
- Full Stack Deep Learning: el aprendizaje automático no se detiene una vez que se construye un modelo (y después de leer lo anterior, sabes que el modelo es una pequeña parte de todo el sistema). Full Stack Deep Learning introduce muchos de los pasos en torno a la construcción de modelos, como el almacenamiento de datos, la manipulación de datos, el versionado de datos (nótese el énfasis en los datos), el despliegue de modelos, así como diferentes herramientas para su implementación.
- Plan de estudios Made with ML MLOps - MLOps = operaciones de aprendizaje automático. Made with ML MLOps está hecho por Goku Mohandas en estilo de aprendizaje, "así es como yo construiría un servicio impulsado por ML y cómo tú también puedes".
- La extraordinaria entrada del blog de LJ Miranda sobre las habilidades de ingeniería de software para los científicos de datos : Si tuviera que escribir una entrada en el blog específicamente sobre cómo pasar de la construcción de modelos (en cuadernos) a la escritura de código completo, sería esta.
[Este post apareció originalmente en el número de abril de 2021 de Machine Learning Monthly, un boletín mensual que escribo con lo último y lo mejor (pero no siempre lo último) del campo del aprendizaje automático].








