Apache Spark vs. Hadoop MapReduce - pros, contras, y cuándo usar cuál
¿Qué es Apache Spark?
La compañía fundada por los creadores de Spark - Databricks - resume su funcionalidad de la mejor manera en su libro Gentle Intro to Apache Spark eBook (lectura altamente recomendada - enlace a la descarga de PDF proporcionado al final de este artículo):
"Apache Spark es un motor de computación unificado y un conjunto de librerías para el procesamiento paralelo de datos en clusters de computadoras. En el momento de escribir este artículo, Spark es el motor de código abierto más activamente desarrollado para esta tarea; convirtiéndolo en la herramienta de facto para cualquier desarrollador o científico de datos interesado en Big Data. Spark soporta múltiples lenguajes de programación ampliamente utilizados (Python, Java, Scala y R), incluye bibliotecas para diversas tareas que van desde SQL hasta streaming y aprendizaje automático, y funciona en cualquier lugar desde un ordenador portátil hasta un clúster de miles de servidores. Esto lo convierte en un sistema fácil de iniciar y escalar hasta el procesamiento de grandes datos a una escala increíblemente grande".
¿Qué es Big Data? Veamos la definición ampliamente usada de Gartner de Big Data, para que luego podamos entender cómo Spark opta por abordar muchos de los desafíos asociados con el trabajo con Big Data en tiempo real a escala:
Nota: La clave aquí es que lo "grande" en Big Data no es sólo el volumen. No sólo se trata de obtener un montón de datos, sino que también viene: rápido en tiempo real, en un formato complejo, y de una variedad de fuentes. De ahí las 3-Vs de Big Data - Volumen, Velocidad, Variedad.
¿Por qué la mayoría de las compañías de Big Data Analytics tienen "spark en la mira" cuando escuchan sobre todas las funcionalidades útiles de Spark?
Basado en mi investigación preliminar, parece que hay tres componentes principales que hacen de Apache Spark el líder para trabajar eficientemente con Big Data a escala, lo que motiva a muchas grandes compañías que trabajan con grandes cantidades de datos no estructurados, a adoptar Apache Spark en su stack.
Spark es un one-stop-shop para trabajar con Big Data - "Spark está diseñado para soportar una amplia gama de tareas de análisis de datos, que van desde la simple carga de datos y consultas SQL hasta el aprendizaje automático y la computación en flujo, sobre el mismo motor de computación y con un conjunto consistente de APIs.
La principal idea que subyace a este objetivo es que las tareas de análisis de datos en el mundo real -ya se trate de análisis interactivos en una herramienta, como un notebook de Jupyter, o de desarrollo de software tradicional para aplicaciones de producción- tienden a combinar muchos tipos y bibliotecas de procesamiento diferentes.
La naturaleza unificada de Spark hace que estas tareas sean más fáciles y eficientes de escribir" (Databricks eBook).
Por ejemplo, si se cargan datos mediante una consulta SQL y luego se evalúa un modelo de aprendizaje automático sobre él utilizando una biblioteca ML de Spark, el motor puede combinar estos pasos en una sola exploración sobre los datos.
Además, los científicos de datos pueden beneficiarse de un conjunto unificado de bibliotecas (por ejemplo, Python o R) al realizar el modelado, y los desarrolladores web pueden beneficiarse de marcos unificados como Node.js o Django.
Spark optimiza su motor central para la eficiencia de los cálculos - "con esto queremos decir que Spark sólo maneja la carga de datos de los sistemas de almacenamiento y la realización de cálculos en ellos, no el almacenamiento permanente como fin en sí mismo.
Spark puede ser usado con una amplia variedad de sistemas de almacenamiento persistente, incluyendo sistemas de almacenamiento en la nube como Azure Storage y Amazon S3, sistemas de archivos distribuidos como Apache Hadoop, almacenes de clave-valor como Apache Cassandra, y buses de mensajes como Apache Kafka.
Sin embargo, Spark no almacena los datos a largo plazo por sí misma ni favorece a ninguno de ellos. La motivación clave aquí es que la mayoría de los datos ya residen en una mezcla de sistemas de almacenamiento.
Los datos son caros de mover, así que Spark se centra en realizar cálculos sobre los datos, sin importar dónde residan" (Databricks eBook). El enfoque de Spark en la computación lo hace diferente de las anteriores grandes plataformas de software de datos como Apache Hadoop.
Hadoop incluía tanto un sistema de almacenamiento (el sistema de archivos Hadoop, diseñado para el almacenamiento de bajo costo sobre clusters de servidores de productos básicos de Defining Spark 4) como un sistema de computación (MapReduce), que estaban estrechamente integrados entre sí.
Sin embargo, esta elección dificulta la ejecución de uno de los sistemas sin el otro o, lo que es más importante, la escritura de aplicaciones que accedan a datos almacenados en cualquier otro lugar. Si bien Spark funciona bien en el almacenamiento Hadoop, actualmente también se utiliza ampliamente en entornos en los que la arquitectura Hadoop no tiene sentido, como la nube pública (en la que el almacenamiento puede adquirirse por separado de la computación) o las aplicaciones de streaming.
Las bibliotecas de Spark le dan una gama muy amplia de funcionalidades - Hoy en día, las bibliotecas estándar de Spark son el grueso del proyecto de código abierto.
El motor central de Spark en sí mismo ha cambiado poco desde de que fue lanzado por primera vez, pero las bibliotecas han crecido para proporcionar cada vez más tipos de funcionalidad, convirtiéndolo en una herramienta multifuncional de análisis de datos.
Spark incluye bibliotecas para SQL y datos estructurados (Spark SQL), aprendizaje automático (MLlib), procesamiento de flujos (Spark Streaming y el más reciente Structured Streaming), y análisis de gráficos (GraphX).
Más allá de estas bibliotecas, hay cientos de bibliotecas externas de código abierto que van desde conectores para varios sistemas de almacenamiento hasta algoritmos de aprendizaje automático.
Apache Spark vs. Hadoop MapReduce... ¿Cuál debería usar?
La respuesta corta es - depende de las necesidades particulares de su negocio, pero basado en mi investigación, parece que 7 de cada 10 veces la respuesta será - Spark. El procesamiento lineal de enormes conjuntos de datos es la ventaja de Hadoop MapReduce, mientras que Spark ofrece un rápido rendimiento, procesamiento iterativo, análisis en tiempo real, procesamiento de gráficos, aprendizaje automático y más.
La gran noticia es que Spark es totalmente compatible con el ecosistema Hadoop y funciona sin problemas con el Sistema de Archivos Distribuidos Hadoop (HDFS), Apache Hive, y otros.
Así que, cuando el tamaño de los datos es demasiado grande para que Spark lo maneje en memoria, Hadoop puede ayudar a superar ese obstáculo a través de su funcionalidad HDFS.
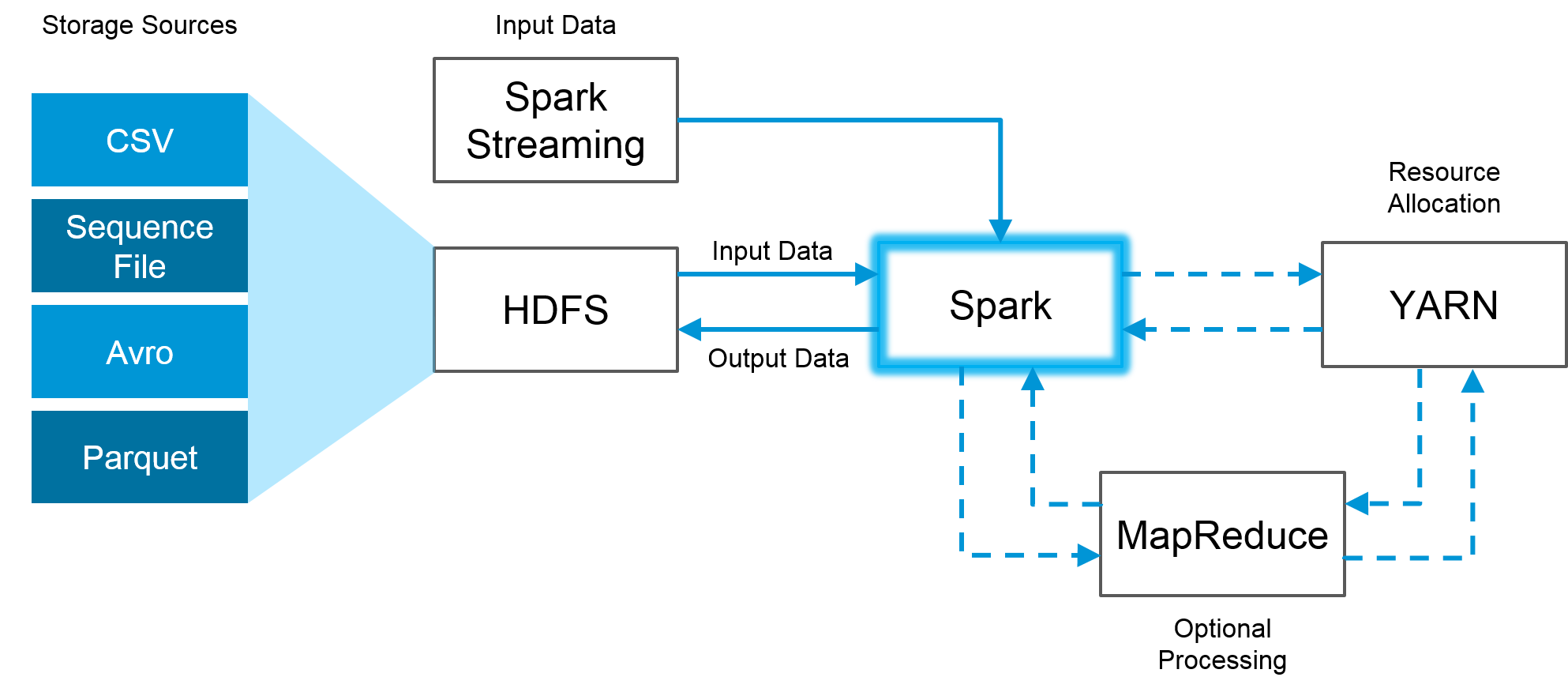
A continuación se muestra un ejemplo visual de cómo Spark y Hadoop pueden trabajar juntos:
La imagen de arriba demuestra cómo Spark utiliza las mejores partes de Hadoop a través del HDFS para leer y almacenar datos, MapReduce para el procesamiento opcional y YARN para la asignación de recursos.
A continuación, trataré de destacar las muchas ventajas de Spark sobre Hadoop MapReduce realizando una breve comparación cara a cara entre ambos.
Apache Spark, es una herramienta de computación en clúster que trabaja a la velocidad de la luz. Spark ejecuta las aplicaciones hasta 100 veces más rápido en memoria y 10 veces más rápido en disco que Hadoop, reduciendo el número de ciclos de lectura-escritura en disco y almacenando los datos intermedios en memoria.
Hadoop MapReduce - MapReduce lee y escribe desde el disco, lo que reduce la velocidad de procesamiento y la eficiencia general.
Facilidad de uso
Apache Spark - Las muchas bibliotecas de Spark facilitan la ejecución de muchos de los principales operadores de alto nivel con RDD (Resilient Distributed Dataset).
Hadoop - En MapReduce, los desarrolladores necesitan codificar a mano cada operación, lo que puede hacer más difícil su uso para proyectos complejos a escala.
Manejo de grandes conjuntos de datos
Apache Spark - ya que Spark está optimizado para la velocidad y la eficiencia computacional al almacenar la mayoría de los datos en la memoria y no en el disco, puede tener un rendimiento inferior al de Hadoop MapReduce cuando el tamaño de los datos es tan grande que la insuficiencia de la memoria RAM se convierte en un problema.
Hadoop - Hadoop MapReduce permite el procesamiento paralelo de grandes cantidades de datos. Rompe un gran trozo en otros más pequeños para ser procesados por separado en diferentes nodos de datos. En caso de que el conjunto de datos resultante sea más grande que la RAM disponible, Hadoop MapReduce puede superar a Spark. Es una buena solución si la velocidad de procesamiento no es crítica y las tareas pueden dejarse en marcha durante la noche para generar resultados por la mañana.
Funcionalidad Apache Spark es el ganador indiscutible en esta categoría. A continuación se muestra una lista de las muchas tareas de Big Data Analytics en las que Spark supera a Hadoop:
Procesamiento iterativo. Si la tarea es procesar datos una y otra vez - Spark derrota a Hadoop MapReduce. Los Resilient Distributed Datasets (RDDs) de Spark permiten múltiples operaciones de mapas en memoria, mientras que Hadoop MapReduce tiene que escribir los resultados provisionales en un disco.
Procesamiento casi en tiempo real. Si una empresa necesita conocimientos inmediatos, entonces debe optar por Spark y su procesamiento en memoria.
Procesamiento de gráficos. El modelo computacional de Spark es bueno para los cálculos iterativos que son típicos en el procesamiento de gráficos. Y Apache Spark tiene GraphX - una API para el cálculo de gráficos.
Aprendizaje automático. Spark tiene MLlib - una biblioteca de aprendizaje automático incorporada, mientras que Hadoop necesita un tercero para proporcionarla. MLlib tiene algoritmos listos para usar que también se ejecutan en memoria.
Uniendo conjuntos de datos. Debido a su velocidad, Spark puede crear todas las combinaciones más rápido, aunque Hadoop puede ser mejor si se unen conjuntos de datos muy grandes que requieren mucha mezcla y clasificación.
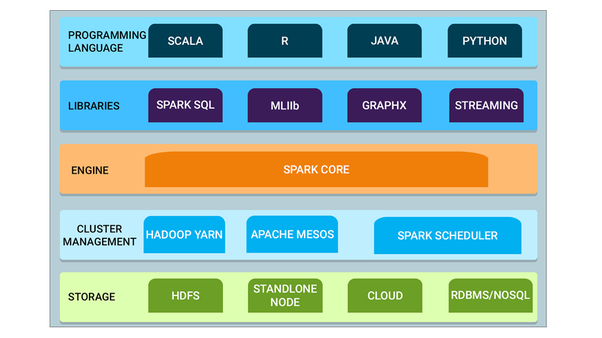
Un resumen visual de las muchas capacidades de Spark y su compatibilidad con otros motores de Big Data y lenguajes de programación:
Spark Core - Spark Core es el motor base para el procesamiento paralelo y distribuido de datos a gran escala. Además, las bibliotecas adicionales que se construyen sobre el núcleo permiten diversas cargas de trabajo para streaming, SQL y aprendizaje automático. Es responsable de la administración de la memoria y la recuperación de fallas, la programación, la distribución y el monitoreo de los trabajos en un clúster y la interacción con los sistemas de almacenamiento.
Administración de clústeres - El administrador de clústeres se utiliza para adquirir recursos de clústeres para la ejecución de trabajos. El núcleo de Spark funciona sobre diversos administradores de clusters, incluyendo Hadoop YARN, Apache Mesos, Amazon EC2 y el administrador de clusters incorporado de Spark. El administrador del clúster se encarga de compartir recursos entre las aplicaciones de Spark. Por otro lado, Spark puede acceder a datos en HDFS, Cassandra, HBase, Hive, Alluxio, y cualquier fuente de datos Hadoop
Spark Streaming - Spark Streaming es el componente de Spark que se utiliza para procesar datos de transmisión en tiempo real.
Spark SQL: Spark SQL es un nuevo módulo en el Spark que integra el procesamiento relacional con la API de programación funcional del Spark. Soporta la consulta de datos ya sea a través de SQL o a través de Hive Query Language. Las API de DataFrame y Dataset de Spark SQL proporcionan un mayor nivel de abstracción para los datos estructurados.
GraphX: GraphX es la API de Spark para gráficos y cálculo paralelo de gráficos. Por lo tanto, extiende Spark RDD con un Resilient Distributed Property Graph.
MLlib (Machine Learning): MLlib significa Machine Learning Library. Spark MLlib se utiliza para realizar el aprendizaje automático en Apache Spark.
Conclusión Con la explosión masiva de Big Data y el aumento exponencial de la velocidad de la potencia de cálculo, herramientas como Apache Spark y otros motores de Big Data Analytics pronto serán indispensables para los científicos de datos y se convertirán rápidamente en el estándar de la industria para la realización de Big Data Analytics y la resolución de complejos problemas empresariales a escala en tiempo real.
¿Qué es SQLite?Conozca el motor de base de datos de SQLite y cómo instalarlo en su ordenador.En este artículo exploraremos el motor de base de datos más extendido llamado SQLite. Describiremos lo que hace, sus principales usos, y luego explicaremos cómo configurarlo y utilizarlo en tu propio ordenador.¿QUÉ ES SQLITE?SQLite es un motor de base de datos. Es un software que permite a los usuarios interactuar con una base de datos relacional. En SQLite, una base de datos se almacena en un único archivo, un rasgo que la distingue de otros motores de base de datos. Este hecho permite una gran accesibilidad: copiar una base de datos no es más complicado que copiar el archivo que almacena los datos, compartir una base de datos puede significar enviar un archivo adjunto de un correo electrónico.INCONVENIENTES DE SQLITELamentablemente, la portabilidad de SQLite hace que sea una mala elección cuando muchos usuarios diferentes están actualizando una tabla al mismo tiempo (para mantener la integridad de los datos, sólo un usuario puede escribir en el archivo a la vez). También puede requerir algo más de trabajo para garantizar la seguridad de los datos privados debido a las mismas características que hacen accesible SQLite. Además, SQLite no ofrece exactamente la misma funcionalidad que muchos otros sistemas de bases de datos, lo que limita algunas características avanzadas que ofrecen otros sistemas de bases de datos relacionales. Por último, SQLite no valida los tipos de datos. Mientras que muchos otros programas de bases de datos rechazarían los datos que no se ajustan al esquema de una tabla, SQLite permite a los usuarios almacenar datos de cualquier tipo en cualquier columna.SQLite crea esquemas que limitan el tipo de datos en cada columna, pero no los aplica. En el ejemplo que figura a continuación se muestra que la columna id espera almacenar números enteros, la columna name espera almacenar texto y la columna age espera almacenar números enteros:CREATE TABLE celebs (
id INTEGER,
name TEXT,
age INTEGER
);Sin embargo, SQLite no rechazará valores del tipo equivocado. Podríamos insertar accidentalmente los tipos de datos equivocados en las columnas. Almacenar diferentes tipos de datos en la misma columna es un mal hábito que puede provocar errores difíciles de corregir, por lo que es importante ser estricto con el esquema aunque SQLite no lo aplique.USOS DE SQLITEIncluso considerando los inconvenientes, los beneficios de poder acceder y manipular una base de datos sin involucrar un servidor son enormes. SQLite se utiliza en todo el mundo para pruebas, desarrollo y en cualquier otro escenario en el que tenga sentido que la base de datos esté en el mismo disco que el código de la aplicación. Los mantenedores de SQLite lo consideran como una de las piezas de software más replicadas del mundo.CONFIGURAR SQLITELos binarios para SQLite se pueden instalar en la página de descarga de SQLite.WINDOWSPara las máquinas de Windows:Descargue el archivo sqlite-tools-win32-x86-3200100.zip y descomprímalo.Desde tu terminal git-bash, abra el directorio de la carpeta descomprimida con cd ~/Descargas/sqlite-tools-win32-x86-3200100/sqlite-tools-win32-x86-3200100/.Intente ejecutar sqlite con el comando winpty ./sqlite3.exe. Si ese comando abre un prompt de sqlite>, ¡felicidades! Has instalado SQLite.Queremos poder acceder a este comando rápidamente desde otro lugar, así que vamos a crear un alias para el comando. Salga del prompt sqlite> escribiendo Ctrl + C, y en la misma terminal de git-bash sin cambiar de carpeta, ejecutar estos comandos:echo "alias sqlite3=\"winpty ${PWD}/sqlite3.exe\"" >> ~/.bashrcysource ~/.bashrcEl primer comando creará el alias sqlite3 que puedes usar para abrir una base de datos. El segundo comando refrescará tu terminal para que puedas empezar a usar este comando. Intenta escribir el comando sqlite3 newdb.sqlite. Si se le presenta un aviso sqlite>, ha creado con éxito el comando sqlite3 para su terminal. Escriba Ctrl + C para salir. También puede salir escribiendo .exit en el prompt y presionando Enter.MAC OS XPara los Mac, usa el paquete de herramientas sqlite de Mac OS X (x86):Instálalo y descomprímelo.En su terminal, navegue hasta el directorio de la carpeta descomprimida usando cd.Ejecute el comando mv sqlite3 /usr/local/bin/. Esto añadirá el comando sqlite3 a la ruta de su terminal, permitiéndole usar el comando desde cualquier lugar.Intente escribir sqlite3 newdb.sqlite. Si se te presenta un sqlite> prompt, ¡has instalado SQLite! Introduce control + d para salir. También puedes salir escribiendo .exit en el prompt y pulsando return.LINUXEn Ubuntu o distribuciones similares:Abra su terminal y ejecute sudo apt-get install sqlite3. De lo contrario, use los administradores de paquetes de su distribución.Intente escribir el comando sqlite3 newdb.sqlite. Si se le presenta un aviso sqlite>, ha creado con éxito el comando sqlite3 para su terminal. Puede salir escribiendo .exit en el prompt y presionando enter.CONCLUSIÓNHa instalado un software de base de datos y ha abierto una conexión a una base de datos. Ahora tiene todo el poder de SQL a su alcance. Podrá gestionar todos los datos de cualquier aplicación que sueñe con escribir. Felicitaciones!
Exploración a fondo de los procesos de recopilación de datos.Algunos de mis repositorios más populares en GitHub han sido sobre la recolección de datos, ya sea a través de web scraping o usando una Interfaz de Programación de Aplicaciones (API). Mi enfoque siempre ha sido encontrar un recurso de donde pueda obtener los datos y luego directamente empezar a buscarlos. Después de recopilar los datos, simplemente los guardo, saco conclusiones y eso es todo.¿Pero qué pasa si quieres compartir los datos? ¿Qué pasa si alguien está buscando este conjunto de datos y no sabe cómo hacerlo? ¿Qué pasa si tienen este conjunto de datos pero no saben lo que significa cada columna o dónde buscar si necesitan más información? Estas preguntas surgen porque el intercambio de datos y la facilidad de uso es importante, pero casi nadie intenta hacer un esfuerzo para que sea reproducible y fácilmente accesible.Aquí es donde surgen las mejores prácticas de recopilación de datos. Los metadatos junto con sus datos son casi tan importantes porque sin ellos sus datos podrían ser inútiles. Vamos a explorar en profundidad, lo que esto es y lo que todo el mundo debe hacer para hacer el proceso de recopilación de datos correcto!Lea También: ¿Cómo Construir Su Portafolio Definitivo De Data Science?Photo by Milan Seitler on UnsplashEmpieza por averiguar qué hay que recolectarPhoto by Edho Pratama on UnsplashEl primer paso, como siempre, es buscar los datos que ya existen. Alguien podría haber recogido un dato similar o el mismo que querías recoger para su problema. Si encuentra un dato de ese tipo, tómelo (si lo pone a disposición) y cite adecuadamente su fuente donde y cuando utilice ese dato para cualquier análisis. Eso es todo!Sin embargo, si no encuentras los datos que necesitas, tendrás que recopilarlos tú mismo. Podría ser una lista de páginas de Wikipedia que saques de su sitio web, información de repositorios que quieras coger para tu cuenta GitHub usando la API de GitHub o datos recogidos de un sensor. Las cosas que puedes recolectar son casi ilimitadas.Lea También: 10 Trucos En Pandas Que Hacen Su Trabajo Más Eficiente.Recopilacion de los datosPhoto by Markus Spiske on UnsplashSea lo que sea que decidas recolectar, comienza a recolectar propios tus datos. Puedes usar BeautifulSoup para extraer información de páginas HTML, acceder a APIs según sea necesario usando su documentación o tal vez crear una aplicación para Android que lea los datos de un sensor y los guarde en un archivo CSV.Una vez que tenga los datos que desea, es posible que desee compartir su trabajo con otros. Querrás que los demás entiendan lo que has recopilado, por qué lo has hecho y tal vez utilizar tus datos citando adecuadamente tu trabajo. Entonces se vuelve esencial tener los datos en un formato apropiado que otros puedan entender y usar.Datos sobre sus datos – MetadatosAhora, te diré algo que siempre usamos pero que a menudo pasamos por alto como parte esencial de los datos. Sí, estoy hablando de los metadatos. La información que te dice lo que significa cada columna, cuáles son las unidades de medida, cuándo se recogieron los datos y mucho más.Entendamos la importancia de los metadatos con un ejemplo. El repositorio de la UCI Machine Learning incluye una larga lista de conjuntos de datos que puedes utilizar para tu análisis y predicción. Elijamos el conjunto de datos sobre el cáncer de mama. Así es como se ve el conjunto de datos:Breast Cancer Data Set (Data)— UCI Machine LearningCon sólo mirar los datos y sin información adicional, no podemos averiguar lo que significa cada columna, y mucho menos hacer un análisis de la misma. Pero justo cuando muestro la siguiente imagen que tiene la descripción de la columna, podemos usar el conjunto de datos, extraer información, realizar análisis exploratorios y hacer predicciones.Breast Cancer Data Set (Attributes) — UCI Machine LearningPor eso la información sobre los datos es realmente importante. Este paso esencial puede hacer o deshacer su conjunto de datos.¿Pero qué es lo que debemos recoger?Photo by Phad Pichetbovornkul on UnsplashSi lo piensas, verás que hay muchas cosas que puedes recopilar como metadatos, como la fecha de recopilación, la ubicación, la descripción de la columna y más. Por lo tanto, existe una colección unificada de estándares de metadatos que uno puede elegir de manera que otros puedan obtener información completa. Algunos de los más comunes son los siguientes:Dublin CoreEl Dublin Core incluye una lista de elementos que hay que especificar sobre los datos como la fecha de creación, el creador y otra información.Norma de codificación y transmisión de metadatosLas normas de codificación y transmisión de metadatos (METS) son una norma de metadatos para datos descriptivos y estructurales representada como el eXtensible Markup Language (XML).Organización Internacional de Normalización (ISO)La ISO define una lista de normas que se siguen en todo el mundo. Las normas pueden variar según el uso y la zona. Por ejemplo, para una forma estándar de representar el tiempo - existe la norma ISO 8601 que significa cómo escribir la fecha y la hora en un patrón comúnmente entendido.Hay otros estándares que también existen, pero el uso depende de los datos que se intentan recoger. El punto básico general cuando se recogen metadatos es que si alguien hoy o en algún momento en el futuro, decide trabajar en sus datos, los datos y metadatos deben ser autosuficientes para describirlo todo.Sin embargo, para hacerlo, hay otra información esencial junto con los metadatos: la procedencia.La procedencia incluye información sobre el proceso de recopilación de datos y si se han realizado transformaciones en esos datos. Mientras se recogen los datos, hacemos un seguimiento de cuándo y cómo se recogieron los datos, los dispositivos de medición, el proceso, el recolector de datos, cualquier limitación, y todo lo relacionado con el proceso de procesamiento de datos (si se hizo).ConclusiónEl paquete completo de datos, junto con los metadatos y la procedencia, hace que los datos sean a prueba de futuro en un formato utilizable.
Trabajo en una compañía de YCombinator que ha desarrollado un interesante grupo interno de científicos de datos. Es un grupo privado, pero recientemente recibió cierta atención en Twitter y pensamos que podría ayudar a los aspirantes a científicos de datos si publicamos algunas de las conversaciones que hemos estado teniendo allí. Twitter estuvo de acuerdo, así que eso es lo que voy a hacer hoy.La primera conversación que voy a publicar comenzó con una pregunta que uno de nuestros compañeros hizo a la comunidad: ¿Cuál es la pregunta más difícil que te han hecho en una entrevista de ciencia de datos?(He cambiado el nombre del solicitante a continuación, pero algunos de los participantes accedieron amablemente a compartir sus nombres completos y enlaces a sus perfiles en línea).Susan Pan pregunta: ¿Cuál es la pregunta más difícil que has encontrado en una entrevista de ciencia de datos?Compartiré la mía: "¿Cuántos años de experiencia tienes en el lenguaje X?" Esto es realmente difícil de responder: ¿Cuento los años que lo usé en la universidad? ¿Cuento los años que lo usé en mis proyectos de hobby? ¿Cuento los años en que lo usé en mi trabajo, pero sólo durante el 15% de mi tiempo?Una vez decidí responder a esta pregunta preguntándole al entrevistador: "¿Puede explicarlo mejor?" Creo que el entrevistador pensó que estaba loco. Espero escuchar sus preguntas más difíciles y tal vez podamos compartir consejos sobre cómo responderlas.La respuesta de Ray Phan: Aquí está la mía: "Si tuvieras que elegir un problema técnico que fuera el más difícil para ti, explica cuál fué y cómo lo resolviste."La razón por la que esto es engañosamente difícil es que te abre a preguntas a medida que avanzas. Pueden decidir hasta dónde o cuán profundo quieren investigar cada parte de su enfoque. De hecho, esta es una pregunta que hago todo el tiempo cuando entrevisto a alguien. Puedes determinar rápidamente si alguien sabe realmente cómo resolver el problema, o si se ha montado en los hombros de otra persona.Curiosamente, esta es la única pregunta que Elon Musk hace durante las entrevistas. (Fuente: Él me entrevistó personalmente cuando me postulé para el Programa de Piloto Automático de Tesla).Susan: ¡Gracias por compartir! Con esta pregunta, ¿estás poniendo a prueba el enfoque de resolución de problemas de un candidato o su profundidad de comprensión de los conceptos técnicos o una mezcla de ambos?Ray: Mezcla de ambos. Quiero ver lo buenos que son a la hora de abordar un problema relativamente desconocido dado su conjunto de habilidades en ese momento, qué habilidades y enfoques aprendieron a lo largo de todo el proceso, y su capacidad de resolución de problemas para determinar si lo resolvieron con éxito.Lea También: ¿Sus Habilidades De Programación Son Los Suficientemente Buenas Para Un Puesto De Trabajo En Data Science?Por la forma en que responden a mis preguntas de seguimiento, así como por el nivel de detalle que comparten conmigo con respecto a cómo lo resuelven, me da una idea bastante buena sobre si son alguien que puede trabajar de forma independiente, puede trabajar en grupo (ya que me están explicando los conceptos y profundizo más) y si confiaría en esa persona al final del día.Por eso dije que esta pregunta es engañosamente difícil porque me dice casi todo sobre la aptitud de la persona en una sola pregunta.Leo Knauth:Mi problema ahora mismo sería: Podría contarles lo que realmente fue el problema más difícil que enfrenté, pero entonces tendría que admitir que me fue mal en ese momento. Realmente mal. Me doy cuenta de que este es un lugar potencial para mostrar crecimiento, pero al final tendría que admitir primero que inicialmente me caí de cara.Si me entrevistara, ¿apreciarías la honestidad? ¿O me recomendaría que eligiera el segundo problema más difícil que he enfrentado, tal vez uno en el que me haya comportado menos miserablemente?Ray: Me gustaría que lo admitieras y me dijeras por qué. El crecimiento es también algo que busco y si no aprendieras nada de eso, entonces no te contrataría... y si la conversación se corta, ¡pasaría al segundo problema!Leo:¡Gracias! Ciertamente necesito practicar este tipo de preguntas de entrevista.Ray:Parte de mi tutoría que hago con mis pupilos es exactamente esta línea de cuestionamiento. Normalmente lo divido en 4 grupos de entrevistas para asegurarme de que el alumno está preparado.Visualización Ajuste técnico ← La pregunta que mencioné anteriormente va aquí Visión para los negocios Ajuste a nuestra cultura coporativa.Lo que trato de hacer es hacer preguntas que los candidatos no se esperan... ...por lo que les insisto en que no se preparen para mis simulacros de entrevistas. Pero sí, ¡práctica! Tu mentor hará, con suerte, las cosas que acabo de decir.La conversación completa fue un poco más larga que esto, y obtuvo un par de respuestas más. Pero la de Ray era mi favorita, porque la pregunta de la entrevista que da te obliga a establecer tu propio nivel de dificultad. Si eliges un problema técnico demasiado fácil, puedes quedar mal; pero si eliges uno demasiado difícil, puedes estropear tu solución, ¡y también quedar mal! Así que tienes que elegir el problema más difícil que estés seguro de poder resolver, que es el objetivo de la pregunta.También es interesante que esta es la única pregunta que Elon Musk hace durante sus entrevistas. Eso es algo que no sabía. Estoy pensando en publicar más de estas conversaciones de Slack en el futuro. De hecho ya hemos continuado con este hilo aqui. Así que si estás interesado en ver las otras respuestas en esta conversación (o en ver las otras), dame un toque en Twitter y házmelo saber. Mi DM está abierto si tienes alguna pregunta.Suponemos que ya eres un experto en responder las preguntas dificiles de una entrevista de trabajo en data science, que tal si ahora pruebas postulandote a diferentes ofertas y pones en practica lo aprendido? Mira estas ofertas de trabajo en data science.Lea También: Consigue Tu Primer Trabajo Como Científico De Datos.
Otra biblioteca de Python para el análisis de datos que deberías conocer - y no, no estoy hablando de Spark o DaskEl análisis de Big Data en Python está teniendo su renacimiento. Todo comenzó con NumPy, que es también uno de los bloques de construcción detrás de la herramienta que estoy presentando en este artículo.Puedes leer más artículos de Data Science en español aquí En 2006, el Big Data era un tema que estaba ganando terreno poco a poco, especialmente con el lanzamiento de Hadoop. Pandas le siguió poco después con sus DataFrames. 2014 fue el año en que Big Data se convirtió en la corriente principal, también Apache Spark fue lanzado ese año. En 2018 llegó Dask y otras librerías para la analítica de datos en Python.Cada mes encuentro una nueva herramienta de Data Analytics, que estoy deseando aprender. Merece la pena invertir una o dos horas en tutoriales, ya que a la larga puede ahorrarte mucho tiempo. También es importante mantenerse en contacto con las últimas tecnologías.Si bien puedes esperar que este artículo sea sobre Dask, estás equivocado. He encontrado otra biblioteca de Python para el análisis de datos que deberías conocer.Al igual que Python, es igual de importante que te hagas con el dominio de SQL. En caso de que no estés familiarizado con él, y tengas algo de dinero de sobra, echa un vistazo a este curso: Master SQL, the core language for Big Data analysis.El análisis de Big Data en Python está teniendo su renacimientoConoce VaexPhoto by Mathew Schwartz on UnsplashVaex es una biblioteca de Python de alto rendimiento para lazy Out-of-Core DataFrames (similar a Pandas), para visualizar y explorar grandes conjuntos de datos tabulares. Puede calcular estadísticas básicas para más de mil millones de filas por segundo. Soporta múltiples visualizaciones que permiten la exploración interactiva de big data. ¿Cuál es la diferencia entre Vaex y Dask?Photo by Stillness InMotion on UnsplashVaex no es similar a Dask, pero sí a los DataFrames de Dask, que están construidos sobre los DataFrames de pandas. Esto significa que Dask hereda los problemas de pandas, como el alto uso de memoria. Este no es el caso de Vaex.Vaex no hace copias de DataFrame por lo que puede procesar DataFrame más grandes en máquinas con menos memoria principal.Tanto Vaex como Dask utilizan el procesamiento "perezoso". La única diferencia es que Vaex calcula el campo cuando es necesario, mientras que con Dask tenemos que utilizar explícitamente la función de cálculo.Los datos deben estar en formato HDF5 o Apache Arrow para aprovechar al máximo las ventajas de Vaex.Puedes leer más artículos de Data Science en español aquí ¿Cómo se instala Vaex?Instalar Vaex es tan sencillo como instalar cualquier otro paquete de Python:pip install vaexVamos a hacer un test drive de Vaex Photo by Eugene Chystiakov on UnsplashVamos a crear un DataFrame de pandas con 1 millón de filas y 1000 columnas para crear un archivo de big data.import vaex
import pandas as pd
import numpy as np
n_rows = 1000000
n_cols = 1000
df = pd.DataFrame(np.random.randint(0, 100, size=(n_rows, n_cols)), columns=['col%d' % i for i in range(n_cols)])
df.head()First few lines in a Pandas Dataframe (image made by author)¿Cuánta memoria principal utiliza este DataFrame?df.info(memory_usage='deep')Guardémoslo en el disco para poder leerlo después con Vaex.file_path = 'big_file.csv'
df.to_csv(file_path, index=False)No ganaríamos mucho leyendo todo el CSV directamente con Vaex ya que la velocidad sería similar a la de pandas. Ambos necesitan aproximadamente 85 segundos en mi portátil.Tenemos que convertir el CSV a HDF5 (el Formato de Datos Jerárquicos versión 5) para ver el beneficio con Vaex. Vaex tiene una función para la conversión, que incluso soporta archivos más grandes que la memoria principal mediante la conversión de trozos más pequeños.Si no puedes abrir un archivo grande con pandas, por limitaciones de memoria, puedes convertirlo a HDF5 y procesarlo con Vaex.Puedes leer más artículos de Data Science en español aquí dv = vaex.from_csv(file_path, convert=True, chunk_size=5_000_000)Esta función crea un archivo HDF5 y lo persigue en el disco. ¿Cuál es el tipo de datos de dv?type(dv)
# output
vaex.hdf5.dataset.Hdf5MemoryMappedAhora, vamos a leer el conjunto de datos de 7,5 GB con Vaex - No necesitaríamos leerlo de nuevo porque ya lo tenemos en la variable dv. Esto es sólo para probar la velocidad.dv = vaex.open('big_file.csv.hdf5')Vaex necesitó menos de 1 segundo para ejecutar el comando anterior. Pero Vaex no leyó realmente el archivo, debido a la carga perezosa, ¿verdad? Vamos a forzar a leerlo calculando una suma de col1.suma = dv.col1.sum()
suma
# Output
# array(49486599)Este me sorprendió mucho. Vaex necesitó menos de 1 segundo para calcular la suma. ¿Cómo es posible? La apertura de estos datos es instantánea, independientemente del tamaño del archivo en el disco. Vaex se limitará a mapear en memoria los datos en lugar de leerlos en memoria. Esta es la forma óptima de trabajar con grandes conjuntos de datos que son mayores que la memoria RAM disponible. Ploteando Vaex también es rápido a la hora de graficar los datos. Dispone de funciones especiales de trazado: plot1d, plot2d y plot2d_contour.dv.plot1d(dv.col2, figsize=(14, 7))Plotting with Vaex (image made by author)Columnas virtuales Vaex crea una columna virtual al añadir una nueva columna, una columna que no ocupa la memoria principal ya que se calcula sobre la marcha.dv['col1_plus_col2'] = dv.col1 + dv.col2
dv['col1_plus_col2']The virtual column in Vaex (image made by author)Filtrado eficiente Vaex no crea copias de DataFrame al filtrar los datos, lo cual es mucho más eficiente en cuanto a la memoria.dvv = dv[dv.col1 > 90]
AggregationsLas agregaciones funcionan de forma ligeramente diferente que en pandas, pero lo más importante es que son rapidísimas. Añadamos una columna virtual binaria donde col1 ≥ 50. dv['col1_50'] = dv.col1 >= 50 Vaex combina la agrupación por y la agregación en un solo comando. El siguiente comando agrupa los datos por la columna "col1_50" y calcula la suma de la columna col3.dv_group = dv.groupby(dv['col1_50'], agg=vaex.agg.sum(dv['col3']))
dv_groupAggregations in Vaex (image made by author)JoinsVaex une datos sin hacer copias de memoria, lo que ahorra la memoria principal. Los usuarios de Pandas estarán familiarizados con la función join:dv_join = dv.join(dv_group, on=’col1_50')Puedes leer más artículos de Data Science en español aquí ConclusiónAl final, te preguntarás: ¿Debemos simplemente cambiar de pandas a Vaex? La respuesta es un gran NO. Pandas sigue siendo la mejor herramienta para el análisis de datos en Python. Tiene funciones bien soportadas para las tareas de análisis de datos más comunes. Cuando se trata de archivos más grandes, pandas puede no ser la herramienta más rápida. Este es un gran momento para usar Vaex. Vaex es una herramienta que deberías añadir a tu caja de herramientas de análisis de datos. Cuando trabajes en una tarea de análisis en la que pandas es demasiado lento o simplemente se bloquea, saca Vaex de tu caja de herramientas, filtra las entradas más importantes y continúa el análisis con pandas. Sígueme en Twitter, donde tuiteo regularmente sobre Ciencia de Datos y Aprendizaje Automático
Daniel Morales
Apr 10, 2020
Join our private community in Discord
Keep up to date by participating in our global community of data scientists and AI enthusiasts. We discuss the latest developments in data science competitions, new techniques for solving complex challenges, AI and machine learning models, and much more!