
El artículo contiene algunos de los conceptos estadísticos avanzados más utilizados junto con su implementación en Python.
En mis artículos anteriores Beginners Guide to Statistics in Data Science y The Inferential Statistics Data Scientists Should Know hemos hablado de casi todos los conceptos básicos (descriptivos e inferenciales) de la estadística que se utilizan comúnmente en la comprensión y el trabajo con cualquier estudio de caso de ciencia de datos. En este artículo, vamos a ir un poco más allá y hablar de algunos conceptos avanzados que no son parte del hype/buzz.
Puedes leer más artículos de Data Science en español aquí
En mis artículos anteriores Beginners Guide to Statistics in Data Science y The Inferential Statistics Data Scientists Should Know hemos hablado de casi todos los conceptos básicos (descriptivos e inferenciales) de la estadística que se utilizan comúnmente en la comprensión y el trabajo con cualquier estudio de caso de ciencia de datos. En este artículo, vamos a ir un poco más allá y hablar de algunos conceptos avanzados que no son parte del hype/buzz.
Puedes leer más artículos de Data Science en español aquí
Concepto #1 - Q-Q(quantile-quantile) Plots
Antes de comprender los gráficos QQ, primero hay que entender qué es un cuantil.
Un cuantil define una parte concreta de un conjunto de datos, es decir, un cuantil determina cuántos valores de una distribución están por encima o por debajo de un determinado límite. Los cuantiles especiales son el cuartil (cuarto), el quintil (quinto) y los percentiles (centésimo).
Un ejemplo:
Si dividimos una distribución en cuatro porciones iguales, hablaremos de cuatro cuartiles. El primer cuartil incluye todos los valores que son menores que la cuarta parte de todos los valores. En una representación gráfica, corresponde al 25% del área total de la distribución. Los dos cuartiles inferiores comprenden el 50% de todos los valores de la distribución. El rango intercuartil entre el primer y el tercer cuartil es igual al rango en el que se encuentra el 50% de todos los valores que se distribuyen alrededor de la media.
En Estadística, un gráfico Q-Q (cuantil-cuantil) es un gráfico de dispersión creado al trazar dos conjuntos de cuantiles entre sí. Si ambos conjuntos de cuantiles provienen de la misma distribución, deberíamos ver los puntos formando una línea que es aproximadamente recta (y=x).
Un cuantil define una parte concreta de un conjunto de datos, es decir, un cuantil determina cuántos valores de una distribución están por encima o por debajo de un determinado límite. Los cuantiles especiales son el cuartil (cuarto), el quintil (quinto) y los percentiles (centésimo).
Un ejemplo:
Si dividimos una distribución en cuatro porciones iguales, hablaremos de cuatro cuartiles. El primer cuartil incluye todos los valores que son menores que la cuarta parte de todos los valores. En una representación gráfica, corresponde al 25% del área total de la distribución. Los dos cuartiles inferiores comprenden el 50% de todos los valores de la distribución. El rango intercuartil entre el primer y el tercer cuartil es igual al rango en el que se encuentra el 50% de todos los valores que se distribuyen alrededor de la media.
En Estadística, un gráfico Q-Q (cuantil-cuantil) es un gráfico de dispersión creado al trazar dos conjuntos de cuantiles entre sí. Si ambos conjuntos de cuantiles provienen de la misma distribución, deberíamos ver los puntos formando una línea que es aproximadamente recta (y=x).

Por ejemplo, la mediana es un cuantil en el que el 50% de los datos caen por debajo de ese punto y el 50% están por encima. El propósito de los gráficos Q Q es averiguar si dos conjuntos de datos proceden de la misma distribución. En el gráfico Q Q se traza un ángulo de 45 grados; si los dos conjuntos de datos proceden de una distribución común, los puntos caerán sobre esa línea de referencia.
Es muy importante saber si la distribución es normal o no para poder aplicar diversas medidas estadísticas a los datos e interpretarlos en una visualización mucho más comprensible para el ser humano, y el gráfico Q-Q entra en escena. La pregunta más fundamental que responde el gráfico Q-Q es si la curva está normalmente distribuida o no.
Se distribuye normalmente, pero ¿por qué?
Los gráficos Q-Q se utilizan para encontrar el tipo de distribución de una variable aleatoria, ya sea una distribución gaussiana, una distribución uniforme, una distribución exponencial o incluso una distribución de Pareto, etc.
Se puede saber el tipo de distribución utilizando la potencia del gráfico Q-Q con sólo mirar el gráfico. En general, hablamos de distribuciones Normales sólo porque tenemos un concepto muy bonito de la regla 68-95-99.7 que se ajusta perfectamente a la distribución normal Así sabemos qué parte de los datos se encuentra en el rango de la primera desviación estándar, la segunda desviación estándar y la tercera desviación estándar de la media. Así que saber si una distribución es Normal nos abre nuevas puertas para experimentar
Es muy importante saber si la distribución es normal o no para poder aplicar diversas medidas estadísticas a los datos e interpretarlos en una visualización mucho más comprensible para el ser humano, y el gráfico Q-Q entra en escena. La pregunta más fundamental que responde el gráfico Q-Q es si la curva está normalmente distribuida o no.
Se distribuye normalmente, pero ¿por qué?
Los gráficos Q-Q se utilizan para encontrar el tipo de distribución de una variable aleatoria, ya sea una distribución gaussiana, una distribución uniforme, una distribución exponencial o incluso una distribución de Pareto, etc.
Se puede saber el tipo de distribución utilizando la potencia del gráfico Q-Q con sólo mirar el gráfico. En general, hablamos de distribuciones Normales sólo porque tenemos un concepto muy bonito de la regla 68-95-99.7 que se ajusta perfectamente a la distribución normal Así sabemos qué parte de los datos se encuentra en el rango de la primera desviación estándar, la segunda desviación estándar y la tercera desviación estándar de la media. Así que saber si una distribución es Normal nos abre nuevas puertas para experimentar

Types of Q-Q plots. Source
Skewed Q-Q plots
Los gráficos Q-Q permiten encontrar la asimetría de la distribución.
Si el extremo inferior del gráfico Q-Q se desvía de la línea recta, pero el extremo superior no, entonces la distribución es Left skewed(Negatively skewed).
Si el extremo inferior del gráfico Q-Q se desvía de la línea recta, pero el extremo superior no, entonces la distribución es Left skewed(Negatively skewed).
Ahora bien, si el extremo superior del gráfico Q-Q se desvía de la línea recta y el inferior no, entonces la distribución es Right skewed(Positively skewed).
Tailed Q-Q plots
Los gráficos Q-Q pueden encontrar la curtosis (medida de la cola) de la distribución.
La distribución con la cola gorda tendrá ambos extremos de la gráfica Q-Q para desviarse de la línea recta y su centro sigue la línea, donde como una distribución de cola delgada término Q-Q parcela con muy menos o desviación insignificante en los extremos por lo que es un ajuste perfecto para la distribución normal.
La distribución con la cola gorda tendrá ambos extremos de la gráfica Q-Q para desviarse de la línea recta y su centro sigue la línea, donde como una distribución de cola delgada término Q-Q parcela con muy menos o desviación insignificante en los extremos por lo que es un ajuste perfecto para la distribución normal.
Supongamos que tenemos el siguiente conjunto de datos de 100 valores:
import numpy as np #create dataset with 100 values that follow a normal distribution np.random.seed(0) data = np.random.normal(0,1, 1000) #view first 10 values data[:10]
array([ 1.76405235, 0.40015721, 0.97873798, 2.2408932 , 1.86755799,
-0.97727788, 0.95008842, -0.15135721, -0.10321885, 0.4105985 ])Para crear un gráfico Q-Q para este conjunto de datos, podemos utilizar la función qqplot() function de la biblioteca statsmodels:
import statsmodels.api as sm import matplotlib.pyplot as plt #create Q-Q plot with 45-degree line added to plot fig = sm.qqplot(data, line='45') plt.show()

En un gráfico Q-Q, el eje x muestra los cuantiles teóricos. Esto significa que no muestra los datos reales, sino que representa dónde estarían los datos si se distribuyeran normalmente.
El eje Y muestra los datos reales. Esto significa que si los valores de los datos caen a lo largo de una línea aproximadamente recta en un ángulo de 45 grados, entonces los datos están distribuidos normalmente.
Podemos ver en nuestro gráfico Q-Q de arriba que los valores de los datos tienden a seguir de cerca el ángulo de 45 grados, lo que significa que los datos están probablemente distribuidos normalmente. Esto no debería ser sorprendente, ya que generamos los 100 valores de datos utilizando el numpy.random.normal() function.
El eje Y muestra los datos reales. Esto significa que si los valores de los datos caen a lo largo de una línea aproximadamente recta en un ángulo de 45 grados, entonces los datos están distribuidos normalmente.
Podemos ver en nuestro gráfico Q-Q de arriba que los valores de los datos tienden a seguir de cerca el ángulo de 45 grados, lo que significa que los datos están probablemente distribuidos normalmente. Esto no debería ser sorprendente, ya que generamos los 100 valores de datos utilizando el numpy.random.normal() function.
Considere en cambio si generamos un conjunto de datos de 100 valores distribuidos uniformemente y creamos un gráfico Q-Q para ese conjunto de datos:
#create dataset of 100 uniformally distributed values data = np.random.uniform(0,1, 1000) #generate Q-Q plot for the dataset fig = sm.qqplot(data, line='45') plt.show()

Los valores de los datos no siguen claramente la línea roja de 45 grados, lo que indica que no siguen una distribución normal.
Concepto #2- Chebyshev's Inequality
En probabilidad, la desigualdad de Chebyshev, también conocida como desigualdad "Bienayme-Chebyshev", garantiza que, para una amplia clase de distribuciones de probabilidad, sólo una fracción definida de valores se encontrará dentro de una distancia específica de la media de una distribución.

La desigualdad de Chebyshev es similar a la regla empírica (68-95-99,7); sin embargo, esta última regla sólo se aplica a las distribuciones normales. La desigualdad de Chebyshev es más amplia; puede aplicarse a cualquier distribución siempre que ésta incluya una varianza y una media definidas.
Así, la desigualdad de Chebyshev dice que al menos (1-1/k^2) de los datos de una muestra deben caer dentro de K desviaciones estándar de la media (o, de forma equivalente, no más de 1/k^2 de los valores de la distribución pueden estar a más de k desviaciones estándar de la media).
Donde K --> número real positivo
Si los datos no se distribuyen normalmente, entonces diferentes cantidades de datos podrían estar en una desviación estándar. La desigualdad de Chebyshev proporciona una manera de saber qué fracción de datos cae dentro de K desviaciones estándar de la media para cualquier distribución de datos.
Lea También: 22 Preguntas Sobre Estadística Para Preparar En Una Entrevista De Trabajo
Así, la desigualdad de Chebyshev dice que al menos (1-1/k^2) de los datos de una muestra deben caer dentro de K desviaciones estándar de la media (o, de forma equivalente, no más de 1/k^2 de los valores de la distribución pueden estar a más de k desviaciones estándar de la media).
Donde K --> número real positivo
Si los datos no se distribuyen normalmente, entonces diferentes cantidades de datos podrían estar en una desviación estándar. La desigualdad de Chebyshev proporciona una manera de saber qué fracción de datos cae dentro de K desviaciones estándar de la media para cualquier distribución de datos.
Lea También: 22 Preguntas Sobre Estadística Para Preparar En Una Entrevista De Trabajo
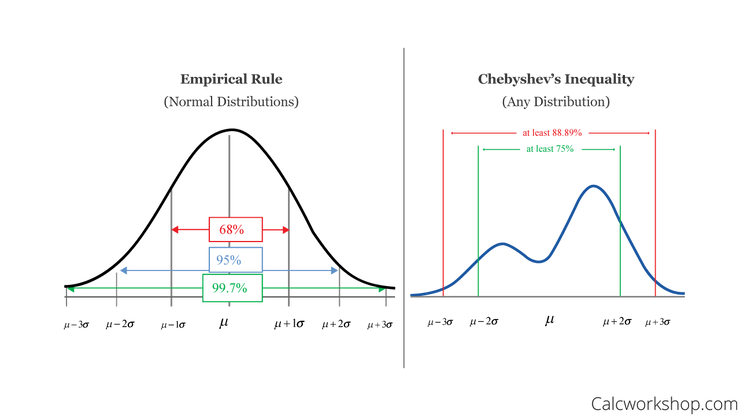
La desigualdad de Chebyshev es de gran valor porque puede aplicarse a cualquier distribución de probabilidad en la que se proporcionen la media y la varianza.
Consideremos un ejemplo: supongamos que se presentan 1.000 concursantes a una entrevista de trabajo, pero sólo hay 70 puestos disponibles. Para seleccionar a los 70 mejores concursantes del total, el propietario realiza unas pruebas para juzgar su potencial. La puntuación media de la prueba es de 60, con una desviación estándar de 6. Si un aspirante obtiene una puntuación de 84, ¿puede presumir que va a conseguir el puesto?
Consideremos un ejemplo: supongamos que se presentan 1.000 concursantes a una entrevista de trabajo, pero sólo hay 70 puestos disponibles. Para seleccionar a los 70 mejores concursantes del total, el propietario realiza unas pruebas para juzgar su potencial. La puntuación media de la prueba es de 60, con una desviación estándar de 6. Si un aspirante obtiene una puntuación de 84, ¿puede presumir que va a conseguir el puesto?

Los resultados muestran que unas 63 personas obtuvieron una puntuación superior a 60, por lo que, con 70 puestos disponibles, un concursante que obtenga una puntuación de 84 puede estar seguro de haber conseguido el puesto.
Chebyshev's Inequality en Python(Source)
Crear una población de 1.000.000 de valores, utilizo una distribución gamma (también funciona con otras distribuciones) con forma = 2 y escala = 2.
import numpy as np import random import matplotlib.pyplot as plt #create a population with a gamma distribution shape, scale = 2., 2. #mean=4, std=2*sqrt(2) mu = shape*scale #mean and standard deviation sigma = scale*np.sqrt(shape) s = np.random.gamma(shape, scale, 1000000)
Ahora muestree 10.000 valores de la población.
#sample 10000 values rs = random.choices(s, k=10000)
Cuente la muestra que tiene una distancia del valor esperado mayor que la desviación estándar k y utilice el recuento para calcular las probabilidades. Quiero representar una tendencia de las probabilidades cuando k aumenta, así que utilizo un rango de k de 0,1 a 3.
#set k
ks = [0.1,0.5,1.0,1.5,2.0,2.5,3.0]
#probability list
probs = [] #for each k
for k in ks:
#start count
c = 0
for i in rs:
# count if far from mean in k standard deviation
if abs(i - mu) > k * sigma :
c += 1
probs.append(c/10000)Traza los resultados:
plot = plt.figure(figsize=(20,10))
#plot each probability
plt.xlabel('K')
plt.ylabel('probability')
plt.plot(ks,probs, marker='o')
plot.show()
#print each probability
print("Probability of a sample far from mean more than k standard deviation:")
for i, prob in enumerate(probs):
print("k:" + str(ks[i]) + ", probability: " \
+ str(prob)[0:5] + \
" | in theory, probability should less than: " \
+ str(1/ks[i]**2)[0:5])
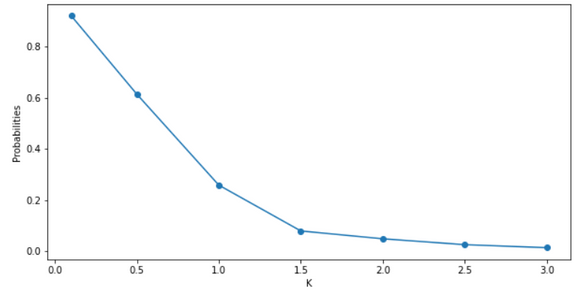
A partir del gráfico y el resultado anteriores, podemos ver que a medida que aumenta k, la probabilidad es decreciente, y la probabilidad de cada k sigue la desigualdad. Además, sólo el caso de que k sea mayor que 1 es útil. Si k es menor que 1, el lado derecho de la desigualdad es mayor que 1, lo que no es útil porque la probabilidad no puede ser mayor que 1.
Concepto #3- Log-Normal Distribution
En teoría de la probabilidad, una distribución logarítmica normal, también conocida como distribución de Galton, es una distribución de probabilidad continua de una variable aleatoria cuyo logaritmo se distribuye normalmente.
Así, si la variable aleatoria X se distribuye de forma log-normal, entonces Y = ln(X) tiene una distribución normal. De forma equivalente, si Y tiene una distribución normal, entonces la función exponencial de Y, es decir, X = exp(Y), tiene una distribución log-normal.
Puedes leer más artículos de Data Science en español aquí
Las distribuciones sesgadas con baja media y alta varianza y todos los valores positivos encajan en este tipo de distribución. Una variable aleatoria con distribución log-normal sólo toma valores reales positivos.
La fórmula general de la función de densidad de probabilidad de la distribución lognormal es
Así, si la variable aleatoria X se distribuye de forma log-normal, entonces Y = ln(X) tiene una distribución normal. De forma equivalente, si Y tiene una distribución normal, entonces la función exponencial de Y, es decir, X = exp(Y), tiene una distribución log-normal.
Puedes leer más artículos de Data Science en español aquí
Las distribuciones sesgadas con baja media y alta varianza y todos los valores positivos encajan en este tipo de distribución. Una variable aleatoria con distribución log-normal sólo toma valores reales positivos.
La fórmula general de la función de densidad de probabilidad de la distribución lognormal es

Los parámetros de localización y escala equivalen a la media y la desviación estándar del logaritmo de la variable aleatoria.
La forma de la distribución Lognormal está definida por 3 parámetros:
La forma de la distribución Lognormal está definida por 3 parámetros:
-
σ es el parámetro de forma, (y es la desviación estándar del logaritmo de la distribución)
-
θ o μ es el parámetro de localización (y es la media de la distribución)
-
m es el parámetro de escala (y es también la mediana de la distribución)
Los parámetros de localización y escala son equivalentes a la media y la desviación estándar del logaritmo de la variable aleatoria, como se ha explicado anteriormente.
Si x = θ, entonces f(x) = 0. El caso en el que θ = 0 y m = 1 se denomina distribución lognormal estándar. El caso en el que θ es igual a cero se denomina distribución lognormal de 2 parámetros.
El siguiente gráfico ilustra el efecto del parámetro de localización(μ) y escala(σ) en la función de densidad de probabilidad de la distribución lognormal:
Si x = θ, entonces f(x) = 0. El caso en el que θ = 0 y m = 1 se denomina distribución lognormal estándar. El caso en el que θ es igual a cero se denomina distribución lognormal de 2 parámetros.
El siguiente gráfico ilustra el efecto del parámetro de localización(μ) y escala(σ) en la función de densidad de probabilidad de la distribución lognormal:

Log-Normal Distribution en Python(Source)
Consideremos un ejemplo para generar números aleatorios a partir de una distribución log-normal con μ=1 y σ=0,5 utilizando la función scipy.stats.lognorm.
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import lognorm
np.random.seed(42)
data = lognorm.rvs(s=0.5, loc=1, scale=1000, size=1000)
plt.figure(figsize=(10,6))
ax = plt.subplot(111)
plt.title('Generate wrandom numbers from a Log-normal distribution')
ax.hist(data, bins=np.logspace(0,5,200), density=True)
ax.set_xscale("log")
shape,loc,scale = lognorm.fit(data)
x = np.logspace(0, 5, 200)
pdf = lognorm.pdf(x, shape, loc, scale)
ax.plot(x, pdf, 'y')
plt.show()
Concepto #4- Power Law distribution
En estadística, una ley de potencia es una relación funcional entre dos cantidades, en la que un cambio relativo en una cantidad da lugar a un cambio relativo proporcional en la otra cantidad, independientemente del tamaño inicial de esas cantidades: una cantidad varía como una potencia de otra.
Por ejemplo, considerando el área de un cuadrado en función de la longitud de su lado, si se duplica la longitud, el área se multiplica por un factor de cuatro.
Una distribución de ley de potencia tiene la forma Y = k Xα,
donde:
Por ejemplo, considerando el área de un cuadrado en función de la longitud de su lado, si se duplica la longitud, el área se multiplica por un factor de cuatro.
Una distribución de ley de potencia tiene la forma Y = k Xα,
donde:
-
X e Y son variables de interés,
-
α es el exponente de la ley,
-
k es una constante.

La distribución de la ley de potencia es sólo una de las muchas distribuciones de probabilidad, pero se considera una herramienta valiosa para evaluar los problemas de incertidumbre que la distribución normal no puede manejar cuando se producen con cierta probabilidad.
Se ha comprobado que muchos procesos siguen leyes de potencia en rangos de valores considerables. Desde la distribución en los ingresos, el tamaño de los meteoroides, las magnitudes de los terremotos, la densidad espectral de las matrices de pesos en las redes neuronales profundas, el uso de las palabras, el número de vecinos en varias redes, etc. (Nota: La ley de potencia aquí es una distribución continua. Los dos últimos ejemplos son discretos, pero a gran escala pueden modelarse como si fueran continuos).
Puedes leer más artículos de Data Science en español aquí
Lea también: Medidas Estadísticas De Tendencia Central
Se ha comprobado que muchos procesos siguen leyes de potencia en rangos de valores considerables. Desde la distribución en los ingresos, el tamaño de los meteoroides, las magnitudes de los terremotos, la densidad espectral de las matrices de pesos en las redes neuronales profundas, el uso de las palabras, el número de vecinos en varias redes, etc. (Nota: La ley de potencia aquí es una distribución continua. Los dos últimos ejemplos son discretos, pero a gran escala pueden modelarse como si fueran continuos).
Puedes leer más artículos de Data Science en español aquí
Lea también: Medidas Estadísticas De Tendencia Central
Power-law distribution en Python(Source)
Trazamos el Pareto distribution que es una forma de distribución de probabilidad de ley de potencia. La distribución de Pareto se conoce a veces como Principio de Pareto o regla "80-20", ya que la regla establece que el 80% de la riqueza de la sociedad está en manos del 20% de su población. La distribución de Pareto no es una ley de la naturaleza, sino una observación. Es útil en muchos problemas del mundo real. Se trata de una distribución sesgada de cola pesada.
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import pareto
x_m = 1 #scale
alpha = [1, 2, 3] #list of values of shape parameters
plt.figure(figsize=(10,6))
samples = np.linspace(start=0, stop=5, num=1000)
for a in alpha:
output = np.array([pareto.pdf(x=samples, b=a, loc=0, scale=x_m)])
plt.plot(samples, output.T, label='alpha {0}' .format(a))
plt.xlabel('samples', fontsize=15)
plt.ylabel('PDF', fontsize=15)
plt.title('Probability Density function', fontsize=15)
plt.legend(loc='best')
plt.show()
Concepto #5- Box cox transformation
La transformación de Box-Cox transforma nuestros datos para que se parezcan a una distribución normal.
Las transformaciones de Box-Cox de un parámetro se definen como En muchas técnicas estadísticas, suponemos que los errores se distribuyen normalmente. Esta suposición nos permite construir intervalos de confianza y realizar pruebas de hipótesis. Al transformar la variable objetivo, podemos (con suerte) normalizar nuestros errores (si no son ya normales).
Además, la transformación de nuestras variables puede mejorar el poder predictivo de nuestros modelos porque las transformaciones pueden eliminar el ruido blanco.
Las transformaciones de Box-Cox de un parámetro se definen como En muchas técnicas estadísticas, suponemos que los errores se distribuyen normalmente. Esta suposición nos permite construir intervalos de confianza y realizar pruebas de hipótesis. Al transformar la variable objetivo, podemos (con suerte) normalizar nuestros errores (si no son ya normales).
Además, la transformación de nuestras variables puede mejorar el poder predictivo de nuestros modelos porque las transformaciones pueden eliminar el ruido blanco.

Distribución original (izquierda) y distribución casi normal después de aplicar la transformación Box cox. Source
En el núcleo de la transformación Box-Cox hay un exponente, lambda (λ), que varía de -5 a 5. Se consideran todos los valores de λ y se selecciona el valor óptimo para sus datos; el "valor óptimo" es el que da como resultado la mejor aproximación a una curva de distribución normal.
Las transformaciones Box-Cox de un parámetro se definen como:
Las transformaciones Box-Cox de un parámetro se definen como:

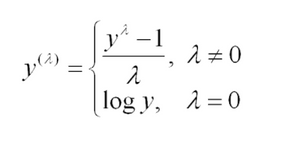
y las transformaciones Box-Cox de dos parámetros como:


Además, la transformación de Box-Cox de un parámetro es válida para y > 0, es decir, sólo para valores positivos, y la transformación de Box-Cox de dos parámetros para y > -λ, es decir, para valores negativos.
El parámetro λ se estima mediante el profile likelihood function y utilizando pruebas de bondad de ajuste.
Si hablamos de algunos inconvenientes de la transformación Box-cox, entonces si lo que se quiere es la interpretación, entonces no se recomienda Box-cox. Porque si λ es algún número distinto de cero, entonces la variable objetivo transformada puede ser más difícil de interpretar que si simplemente aplicamos una transformación logarítmica.
Puedes leer más artículos de Data Science en español aquí
Un segundo escollo es que la transformación Box-Cox suele dar la mediana de la distribución de la previsión cuando revertimos los datos transformados a su escala original. En ocasiones, queremos la media y no la mediana.
El parámetro λ se estima mediante el profile likelihood function y utilizando pruebas de bondad de ajuste.
Si hablamos de algunos inconvenientes de la transformación Box-cox, entonces si lo que se quiere es la interpretación, entonces no se recomienda Box-cox. Porque si λ es algún número distinto de cero, entonces la variable objetivo transformada puede ser más difícil de interpretar que si simplemente aplicamos una transformación logarítmica.
Puedes leer más artículos de Data Science en español aquí
Un segundo escollo es que la transformación Box-Cox suele dar la mediana de la distribución de la previsión cuando revertimos los datos transformados a su escala original. En ocasiones, queremos la media y no la mediana.
Box-Cox transformation en Python (Source)
El paquete stats de SciPy proporciona una función llamada boxcox para realizar la transformación de potencia box-cox que toma los datos originales no normales como entrada y devuelve los datos ajustados junto con el valor lambda que se utilizó para ajustar la distribución no normal a la distribución normal.
#load necessary packages
import numpy as np
from scipy.stats import boxcox
import seaborn as sns
#make this example reproducible
np.random.seed(0)
#generate dataset
data = np.random.exponential(size=1000)
fig, ax = plt.subplots(1, 2)
#plot the distribution of data values
sns.distplot(data, hist=False, kde=True,
kde_kws = {'shade': True, 'linewidth': 2},
label = "Non-Normal", color ="red", ax = ax[0])
#perform Box-Cox transformation on original data
transformed_data, best_lambda = boxcox(data)
sns.distplot(transformed_data, hist = False, kde = True,
kde_kws = {'shade': True, 'linewidth': 2},
label = "Normal", color ="red", ax = ax[1])
#adding legends to the subplots
plt.legend(loc = "upper right")
#rescaling the subplots
fig.set_figheight(5)
fig.set_figwidth(10)
#display optimal lambda value
print(f"Lambda value used for Transformation: {best_lambda}")

Concepto #6- Poisson distribution
En la teoría de la probabilidad y la estadística, la distribución de Poisson es una distribución de probabilidad discreta que expresa la probabilidad de que se produzca un número determinado de sucesos en un intervalo fijo de tiempo o espacio si estos sucesos se producen con una tasa media constante conocida y con independencia del tiempo transcurrido desde el último suceso.
En términos muy sencillos, una distribución de Poisson puede utilizarse para estimar la probabilidad de que algo ocurra "X" número de veces.
Algunos ejemplos de procesos de Poisson son los clientes que llaman a un centro de ayuda, la desintegración radiactiva de los átomos, los visitantes de una página web, los fotones que llegan a un telescopio espacial y los movimientos en el precio de las acciones. Los procesos de Poisson suelen estar asociados al tiempo, pero no tienen por qué estarlo.
La fórmula de la distribución de Poisson es:
En términos muy sencillos, una distribución de Poisson puede utilizarse para estimar la probabilidad de que algo ocurra "X" número de veces.
Algunos ejemplos de procesos de Poisson son los clientes que llaman a un centro de ayuda, la desintegración radiactiva de los átomos, los visitantes de una página web, los fotones que llegan a un telescopio espacial y los movimientos en el precio de las acciones. Los procesos de Poisson suelen estar asociados al tiempo, pero no tienen por qué estarlo.
La fórmula de la distribución de Poisson es:


Donde:
-
e es el numero de Euler (e = 2.71828...)
-
k es el numero de ocurrencias
-
k! es el factorial de k k
- λ es igual al valor esperado de kcuando éste es también igual a su varianza
Lambda(λ) puede considerarse como el número esperado de eventos en el intervalo. A medida que cambiamos el parámetro de la tasa, λ, cambiamos la probabilidad de ver diferentes números de eventos en un intervalo. El siguiente gráfico es la función de masa de probabilidad de la distribución de Poisson que muestra la probabilidad de que se produzca un número de sucesos en un intervalo con diferentes parámetros de tasa.

Función de masa de probabilidad para la distribución de Poisson con parámetros de tasa variables. Source
La distribución de Poisson también se utiliza habitualmente para modelar datos de recuento financiero en los que el recuento es pequeño y a menudo es cero. Por ejemplo, en finanzas, puede utilizarse para modelar el número de operaciones que un inversor típico realizará en un día determinado, que puede ser 0 (a menudo), o 1, o 2, etc.
Otro ejemplo: este modelo puede utilizarse para predecir el número de "shocks" del mercado que se producirán en un periodo de tiempo determinado, por ejemplo, durante una década.
Otro ejemplo: este modelo puede utilizarse para predecir el número de "shocks" del mercado que se producirán en un periodo de tiempo determinado, por ejemplo, durante una década.
Poisson distribution en Python
from numpy import random
import matplotlib.pyplot as plt
import seaborn as sns
lam_list = [1, 4, 9] #list of Lambda values
plt.figure(figsize=(10,6))
samples = np.linspace(start=0, stop=5, num=1000)
for lam in lam_list:
sns.distplot(random.poisson(lam=lam, size=10), hist=False, label='lambda {0}'.format(lam))
plt.xlabel('Poisson Distribution', fontsize=15)
plt.ylabel('Frequency', fontsize=15)
plt.legend(loc='best')
plt.show()
A medida que λ se hace más grande, el gráfico se parece más a una distribución normal.
Espero que hayas disfrutado de la lectura de este artículo, Si tienes alguna pregunta o sugerencia, por favor deja un comentario.
Lea también: Falsos Positivos Vs. Falsos Negativos
Siéntase libre de conectarse conmigo en LinkedIn para cualquier consulta.
Espero que hayas disfrutado de la lectura de este artículo, Si tienes alguna pregunta o sugerencia, por favor deja un comentario.
Lea también: Falsos Positivos Vs. Falsos Negativos
Siéntase libre de conectarse conmigo en LinkedIn para cualquier consulta.




